16.1. 计数与统计
- 示例
select count(*) from lxdb_key_val ;
select count(*),sum(i1),max(i2),min(i1) from lxdb_key_val ;
- 关于avg平均数
目前的版本不支持avg,如果要计算avg请嵌套一层-不然性能很差
with tmp as (select count(*) cnt,sum(i2) s1,count(i2) s2 from lxdb_key_val)
select cnt, CASE WHEN s2>0 THEN s1/s2 ELSE null END as avg,s1,s2 from tmp ;
16.2. 分组统计
select txt1,count(*) from lxdb_key_val group by txt1 limit 10;
select txt1,txt2,count(*) from lxdb_key_val where txt1='txt2' group by txt1,txt2 limit 10;
select txt2, count(*),sum(i2),max(i2),min(i2) from lxdb_key_val group by txt2 limit 10;
select txt1,count(*) from lxdb_key_val where txt1='txt2' group by txt1 limit 10;
16.3. 统计在存储类型上的取舍
通过倒排表进行统计,即store中含有i选项
1:但只能支持单列的count(*)统计,也不支持基数超过1024的列 2:只支持text类型,不支持数值型 3:性能可以达到5亿/秒/节点,适用于标签等稀疏列的count(*)统计基于列存的统计性能,即store中含有d选项
1:支持多列,支持sum,max,min,count等统计 2:支持数组类型 3:性能很慢,需要结合cache,将列存防止在内存中,才能提升性能
16.4. 高基数分组上的问题
- 问题
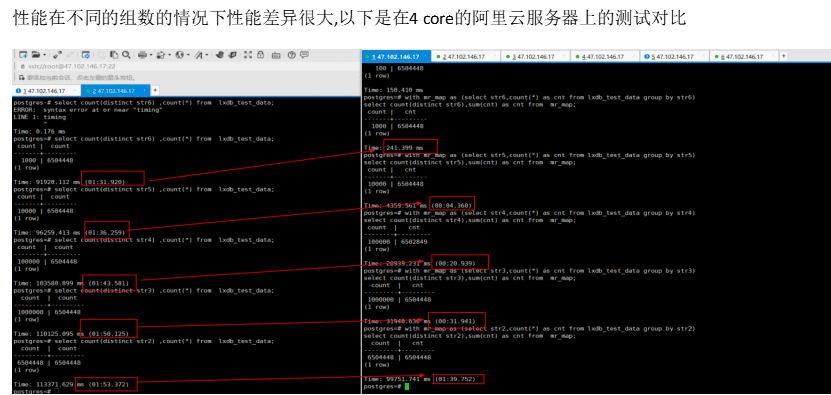
如果组数太多,会在索引层聚合成多个相同名字的组抛给db,这就需要在db层进行二次聚合.目前配置超过5120个组,就会抛给db层,会导致db会有同一个组被拆分成2个组的情况
如:
select * from (select str4,count(*) from lxdb_test_data group by str4) tmp where lower(str4)='1' limit 10;
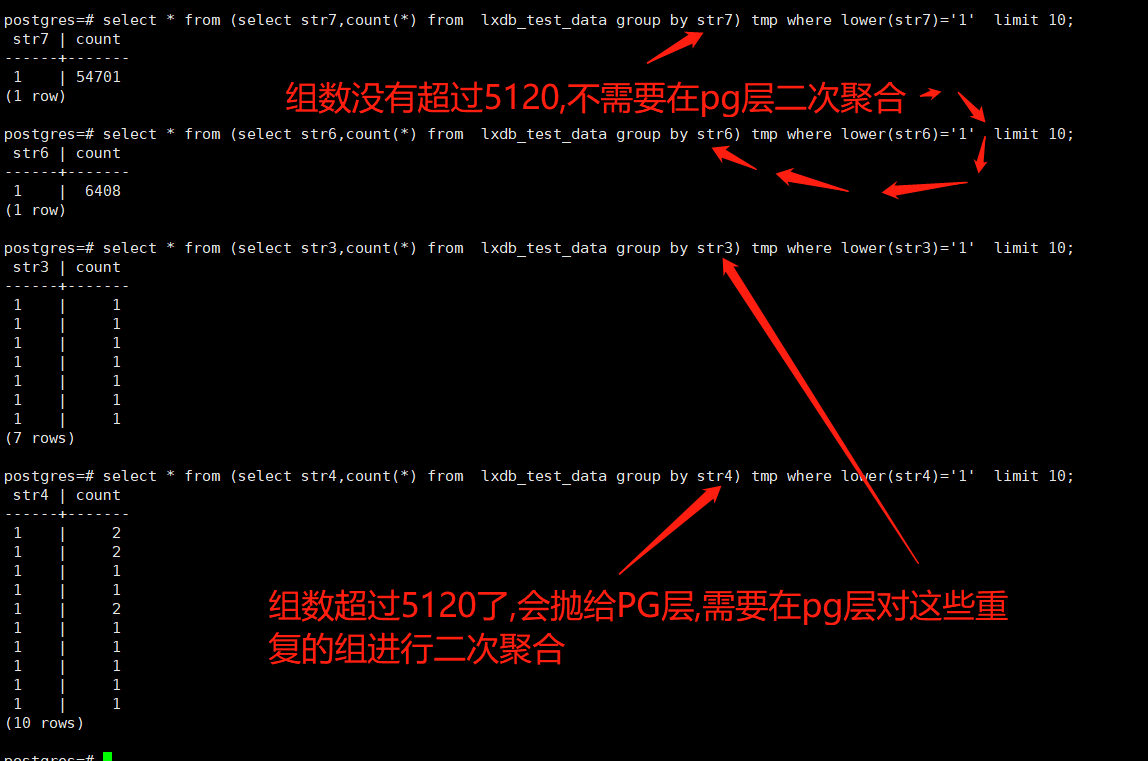
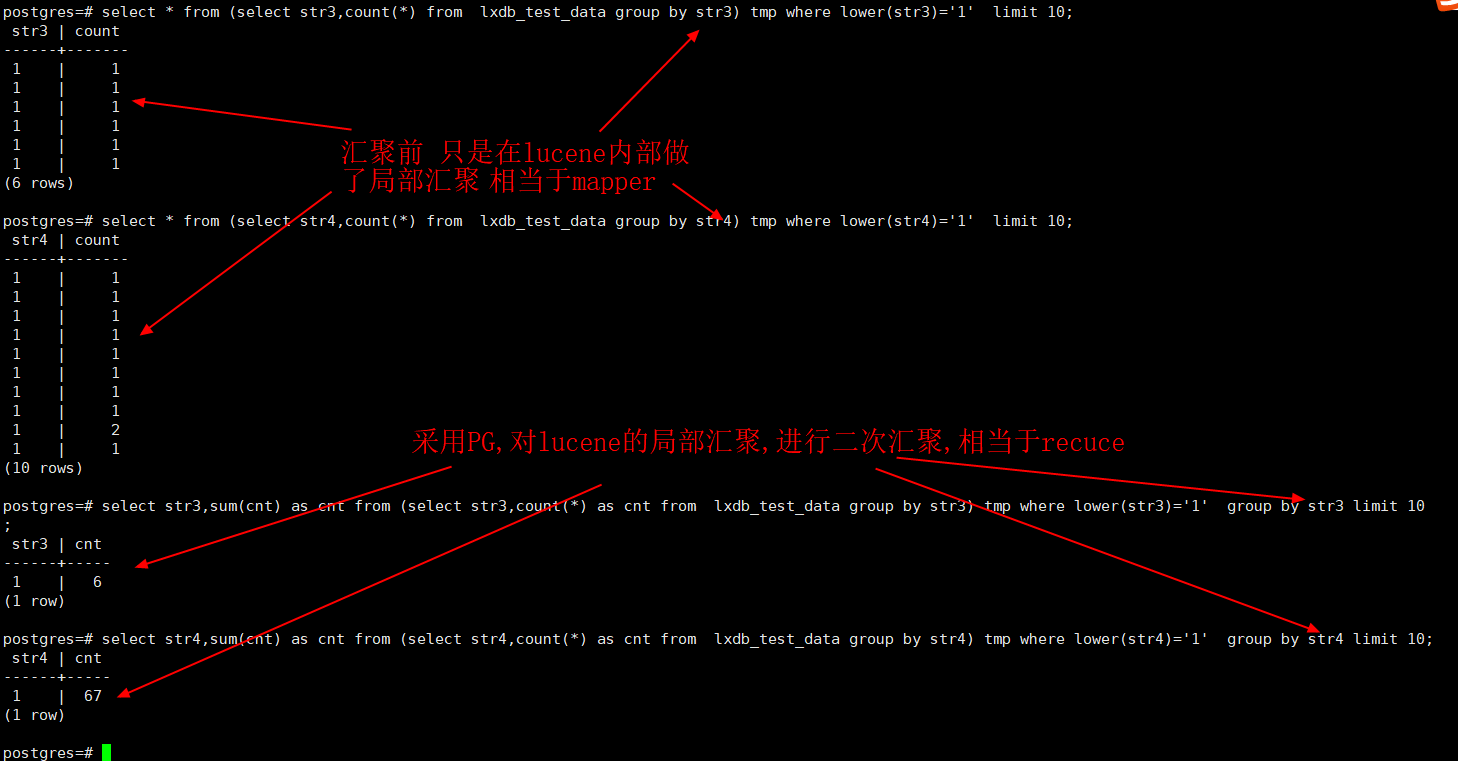
- 如何解决(性能依然低下)
在db层二次汇聚,具体用法如下(考虑到性能这里是非标准SQL,改变了语义)
select str3,sum(cnt) as cnt from (select str3,count(*) as cnt from lxdb_test_data group by str3) tmp where lower(str3)='1' group by str3 limit 10;
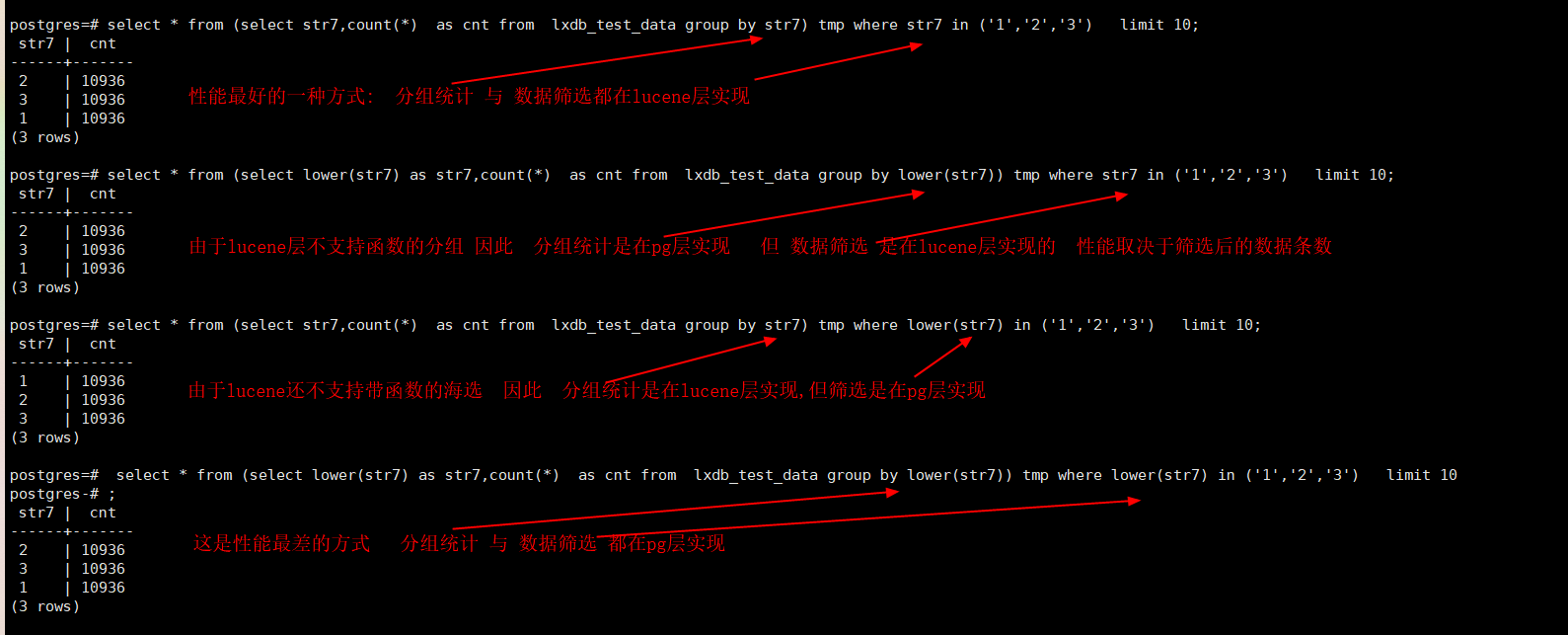
16.5. 分组计算的计算下沉
16.6. 去重统计