lxdb从3.0版本之前是将数据存储在本地文件系统,lxdb 3.0以及之后的版本将数据存储在分布式文件系统之上,下面是使用本地文件系统与分布式文件系统优缺点对比以及录信在分布式文件系统之上的技术创新.
2.1. 硬盘存储与计算均衡上的比较
LXDB采用分片(shard)的方式进行分布式计算与存储
1)Lxdb2.0 使用本地硬盘
其特点如下:
- 数据存储在操作系统的本地硬盘,存储与计算的粒度是一个分片
- 一个分片只能使用一块硬盘
- 一个分片只能在一台物理设备上进行计算.
在实际的生产环境上,不同的数据表之间数据差异很大,这会导致如下问题
- 不同硬盘之间存储差异很大,有些硬盘存储的很满,而有一些硬盘很空闲
- 有些表查询频繁硬盘很繁忙,而有些表则很闲,资源利用率太低
- 如果分片太大,一台机器计算资源不够,不能使用多台设备进行计算
- 数据迁移,设备下架,扩容,要么停服务,要么rebalance,对系统冲击很大
- 单块硬盘无法扩空间,后期数据库容量不够,没法通过加硬盘扩容
2)Lxdb3.0 采用分布式文件系统
- 数据按块大小切分到多个机器的多个硬盘中,硬盘存储均衡
- 在读取和写入的时候,所有硬盘均参与读写,没有硬盘闲着不干活,资源利用率高
- 同一个分片,跨多个设备计算,使用多台的计算资源
- 分布式文件系统,数据迁移,下架,扩容无感知,不影响服务
- 后期容量不够,随时随地添加硬盘扩充存储
2.2. 在集群规模上
1) Lxdb2.0使用本地硬盘. 一般适合100节点以下
随着节点数增多,硬盘管理复杂,在大规模集群环境下,每台设备的硬盘个数,硬盘容量不可能统一,甚至同一台设备后期扩硬盘的硬盘大小也与前期的容量不同,上千节点的集群几乎每周都有硬盘损坏,使用本地文件系统会在后期节点规模变大后导致集群管理异常复杂,因此采用本地文件系统的方案不适合大的集群规模.业界也几乎没有单个集群上千节点的案例
2) LXDB3.0使用分布式文件系统, 能管理上万以上的节点
分布式文件系统,节点上万的案例太多了,能非常好的兼容大小硬盘,存储容量可以随时动态扩充,数据迁移,容错均不需要额外考虑.
2.3. 在容错性上
1)LXDB2.0使用本地文件系统以来raid机制进行容错,缺点是
- raid需要机房天天有人巡检,尤其是大规模集群,巡检的工作量不小.以raid5为例,如果一台机器损坏一块硬盘,则需要及时的更换硬盘,否则第二块硬盘损坏后整体数据不可恢复
- 另外raid机制的备份本质是单机备份,如果这台机器损坏,则数据丢失不可恢复
2)LXDB3.0使用分布式文件系统,跨机多副本备份
- 无需天天巡检,只要容量足够,硬盘损坏,缺失副本,集群会自动在别的硬盘补足副本,不会因为硬盘的连续损坏导致数据丢失
- 副本的是备份是跨机器或者块机架,跨机房的备份,不会应为某台设备的损坏导致数据丢失。
2.4. 灵活性上
- 基于分布式文件系统:存储上可以随时扩盘,移除硬盘,比较弹性。
- 基于分布式文件系统:计算上可以随时通过扩机器提高算力,不受分片数制约。
- 基于分布式文件系统:某台设备挂了,可以立即切换服务到别的机器上,容错性好。
2.5. 针对hdfs随机读性能太差的解决
1) lxdb的数据写入依然采用hdfs的API,由于是顺序写入,不存在瓶颈。
2) lxdb的查询,统计则直接将计算下推到DN的内部,直接使用本地盘,从而规避通过hdfs的API因反复的锁调用,导致性能低下的问题。在大规模系统中,这往往能减少成千上万倍的DN调用,从而使得lxdb使用HDFS性能与吞吐量更接近本地文件系统的性能。
3) lxdb的更新也会将更新下推到DN的内部,直接使用本地盘,这使得基于hdfs之上的更新效率得以成千上万倍的提升。
4) lxdb与NN的交互采用的是批量接口,避免频繁的访问NN
5) lxdb会采用本地盘与HDFS结合的方式,那些不怕丢失的临时文件采用本地硬盘存储,用后立即删除,至少降低NN的10倍的请求次数,且因将小文件进行了合并比传统Lucene减少了至少十倍以上的文件数量。
2.6. 针对小文件太多影响入库和hdfs性能问题
由于lucene的特性会频繁创建和删除小文件,会导致整体hadoop的吞吐量非常低下(hadoop不适合小文件存储),针对这个问题我们进行了如下改造
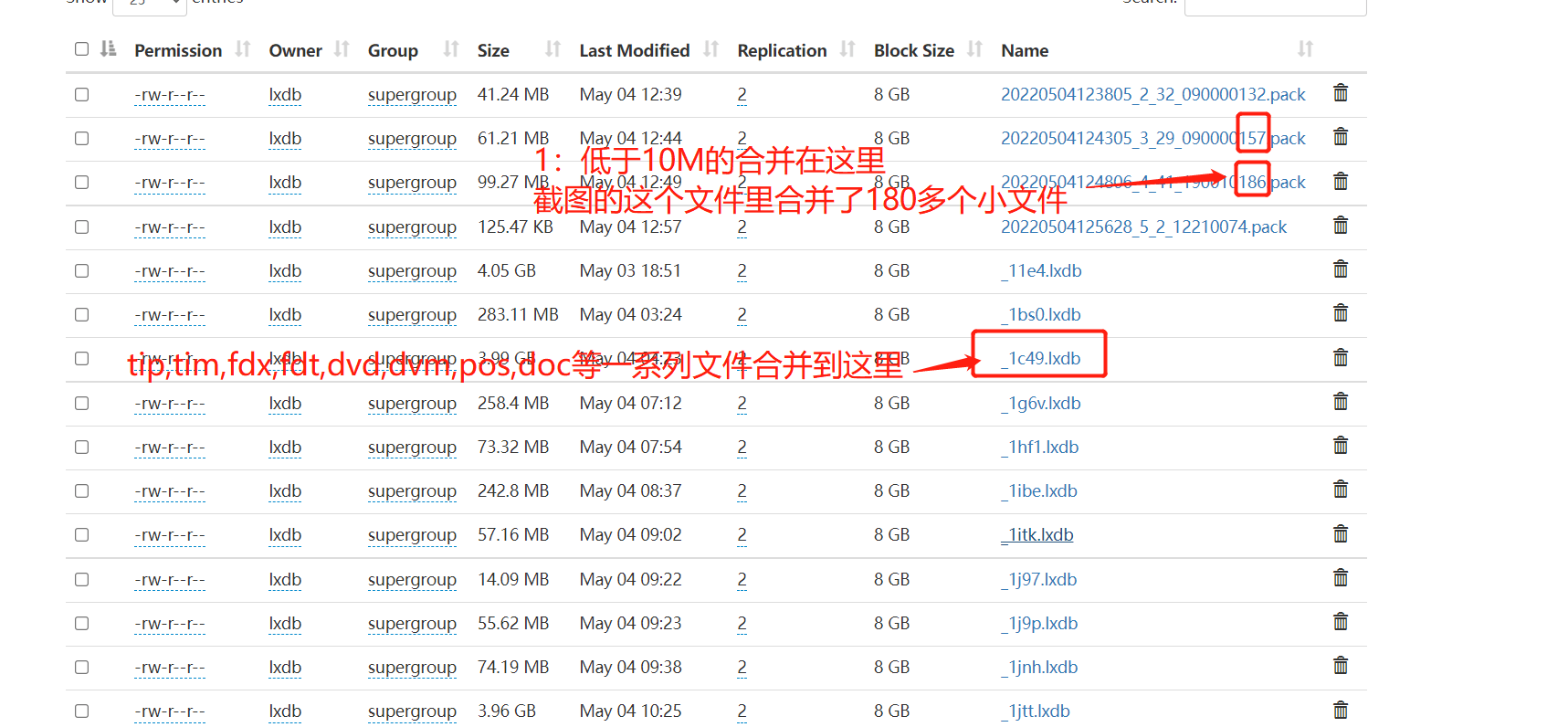
1:lxdb会将低于10M的小文件一起打包,通过这个特性,我们实测减少了10倍的文件反复的创建和删除
2:我们将一些临时文件,合并,10多个不同种类的文件合并到一个文件中,从而减少hdfs中的文件数量,通过这个方法,大约能减少10倍左右的文件数量
通过以上两步,lxdb创建文件的数量相对于开源的基于hdfs的索引实现,减少了2个数量级。