lxdb支持多表关联,但关联涉及较大的数据迁移,如果命中数据较多,建议慎用.
目前lxdb对于多表关联还仅仅是功能上的支持,其内部并没有真正使用索引直接关联,这是我们今后需要改进的地方.
28.1. 数据准备
1.准备左表数据
CREATE FOREIGN TABLE join1 (
ukey text OPTIONS(key 'unique'),
i1 int,
i2 int,
txt1 text,
txt2 text
) SERVER lxdb options(store 'ids');
select create_distributed_table('join1', 'ukey','hash','default',3);
INSERT INTO join1(ukey,i1, i2, txt1,txt2) VALUES ('1111',1111, 2, 'left1', 'left2');
INSERT INTO join1(ukey,i1, i2, txt1,txt2) VALUES ('1112',1112, 4, 'left1', 'left2');
INSERT INTO join1(ukey,i1, i2, txt1,txt2) VALUES ('1113',1113, 6, 'left1', 'left2');
INSERT INTO join1(ukey,i1, i2, txt1,txt2) VALUES ('1114',1114, 8, 'left1', 'left2');
INSERT INTO join1(ukey,i1, i2, txt1,txt2) VALUES ('0000',0000, 8, 'left1', 'left2');
2.准备右表数据
CREATE FOREIGN TABLE join2 (
ukey text OPTIONS(key 'unique'),
i1 int,
i2 int,
txt1 text,
txt2 text
) SERVER lxdb options(store 'ids');
select create_distributed_table('join2', 'ukey','hash','default',3);
INSERT INTO join2(ukey,i1, i2, txt1,txt2) VALUES ('1111',1111, 2, 'right1', 'right2');
INSERT INTO join2(ukey,i1, i2, txt1,txt2) VALUES ('1112',1112, 4, 'right1', 'right2');
INSERT INTO join2(ukey,i1, i2, txt1,txt2) VALUES ('1113',1113, 6, 'right1', 'right2');
INSERT INTO join2(ukey,i1, i2, txt1,txt2) VALUES ('1114',1114, 8, 'right1', 'right2');
INSERT INTO join2(ukey,i1, i2, txt1,txt2) VALUES ('9999',9999, 8, 'right1', 'right2');
28.2. 按照分片列进行关联
默认lxdb的关联支持按照分片列进行关联,其效率相对非分片列的关联(依然没使用索引)
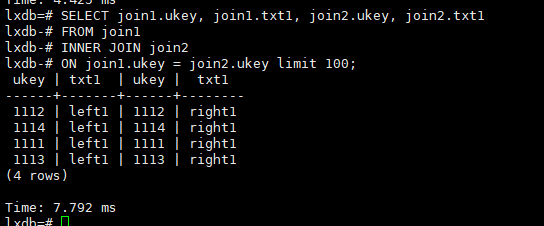
1.基本写法
inner join
SELECT join1.ukey, join1.txt1, join2.ukey, join2.txt1
FROM join1
INNER JOIN join2
ON join1.ukey = join2.ukey limit 100;
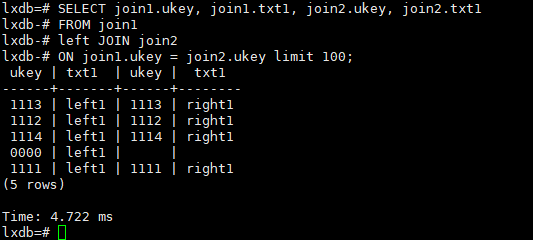
left join
SELECT join1.ukey, join1.txt1, join2.ukey, join2.txt1
FROM join1
left JOIN join2
ON join1.ukey = join2.ukey limit 100;
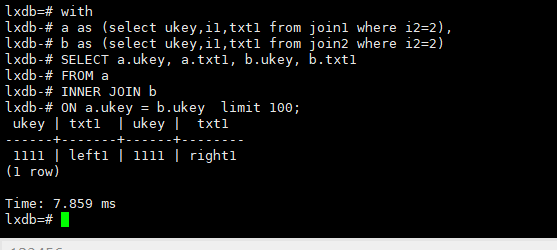
2.筛选后在join
很多时候,我们需要在join前筛选数据,以提交效率,可以结合with as 写法
,这里筛选条件是可以下推到后面的索引层的
with
a as (select ukey,i1,txt1 from join1 where i2=2),
b as (select ukey,i1,txt1 from join2 where i2=2)
SELECT a.ukey, a.txt1, b.ukey, b.txt1
FROM a
INNER JOIN b
ON a.ukey = b.ukey limit 100;
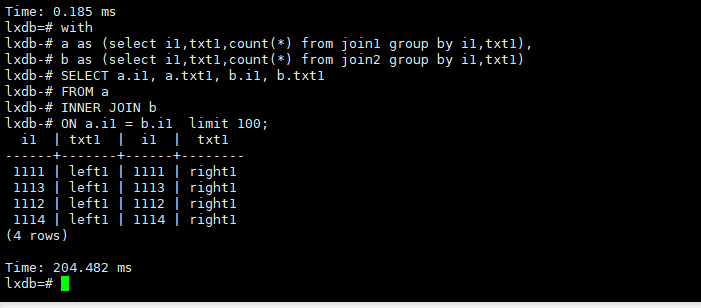
28.3. 非分片列的join
默认lxdb是不支持非分片列的join的,但可以考虑两种变通方式,但并非是分布式的.而是将数据抛到CN节点,如果抛出数据太多,一定要结合where限制每张表返回的数据规模
1.第一种通过设置
set citus.enable_repartition_joins = on;
如果不加会报错
set citus.enable_repartition_joins = on;]()
SELECT join1.i1, join1.txt1, join2.i1, join2.txt1
FROM join1
INNER JOIN join2
ON join1.i1 = join2.i1 where join1.i2=2 and join2.i2=2 limit 100;
2.第二种通过group by聚合后在join(变成单分片模式)
with
a as (select i1,txt1,count(*) from join1 where i2=2 group by i1,txt1 ),
b as (select i1,txt1,count(*) from join2 where i2=2 group by i1,txt1)
SELECT a.i1, a.txt1, b.i1, b.txt1
FROM a
INNER JOIN b
ON a.i1 = b.i1 limit 100;
3.第三种通过with as 声明成临时数据集
with
a as (select i1,txt1 from join1 where i2=2),
b as (select i1,txt1 from join2 where i2=2)
SELECT a.i1, a.txt1, b.i1, b.txt1
FROM a
INNER JOIN b
ON a.i1 = b.i1 limit 100;