4.5. 数据操作
4.5.1 数据导入
1. 生成数据

图 4.5.1.1伪造数据
2. 追加数据
./load.sh -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
-f 的路径表示在hdfs的文件路径
3. 覆盖数据
./load.sh -ov -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
4. 按条件删除
./load.sh -cond "s1='1'" -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
5. 按指定的k列进行更新
./load.sh -k s1 -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
6. 按照指定k列进行更新,并按照k列进行排重
- 按照-k指定的字段 进行覆盖更新;
- 通过-dist 会将传入的数据按照-k指定的字段进行排重,排重规则为:根据文件偏移量选择最大偏移量的数据(要求相同的key在同一个文件内)
./load.sh -k s1 -dist -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
7. 按照指定k列进行删除
./load.sh -k s1 -delete -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
8. 按指定的k列进行部分数据更新,部分数据删除
(1) 使用样例
./load.sh -k s1 -dist -deletemark i1 -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2
(2) 具体方法
本功能解决通过ogg传入过来的数据,导入到lsql里的方法,里面有新增,有删除,有更新操作,为了保证数据一致性。
注意,可以一次执行多个文件,但切记,同一个ID只能出现在一个文件内,会根据文件偏移量计算那条数据时最新的,最终只会保留在当前文件内偏移量最大的那个。
导入命令说明:
-k 表示唯一id,这里写uniqkey -dist 表示按照key导入的时候进行数据排重,相同的key只保留在文件内偏移量最大的那个值 -deletemark 表示该条记录是否是被删除的记录,如果其值为 D or delete 会被删除,区分大小写,如果不是这两个值,会覆盖 ./load.sh -t ogg_test -p 20191231 -k uniqkey -dist -deletemark datastatus -tp txt -f a.txt -local -sp , -fl uniqkey,dataname,datapos,dataversion,datastatus建表语句
create table ogg_test( uniqkey y_string_id, dataname y_string_id, datapos y_string_id, dataversion y_string_id, datastatus y_string_id )第一次导入数据
代码框内味导入数据内容:
数据id,数据名称,文件内位置(我们自己校验用),数据版本,删除标记
1,数据1,第1条,0001,- 2,数据2,第2条,0001,- 3,数据3,第3条,0001,- 4,数据4,第4条,0001,- 5,数据5,第5条,0001,- 6,数据6,第6条,0001,- 7,数据7,第7条,0001,- 8,数据8,第8条,0001,- 9,数据9,第9条,0001,- 9,数据9,第10条,0001,入库脚本如下:
./load.sh -t ogg_test -p 20191231 -k uniqkey -dist -deletemark datastatus -tp txt -f a.txt -local -sp , -fl uniqkey,dataname,datapos,dataversion,datastatus入库结果为:
select * from ogg_test where partition like '20191231' order by uniqkey asc limit 20;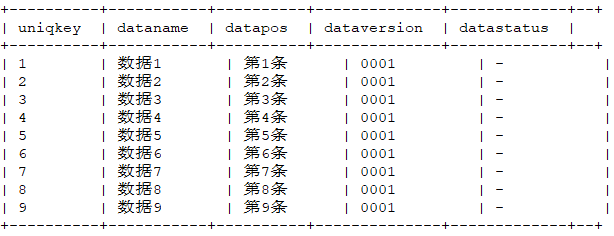
第二次导入,部分数据更新,部分数据删除
数据内容:
1,数据1,第1条,0002,U 2,数据2,第2条,0002,D 3,数据3,第3条,0002,D 3,数据3,第4条,0002,A 4,数据4,第5条,0002,U 5,数据5,第6条,0002,D 6,数据6,第7条,0002,U 7,数据7,第8条,0002,U 7,数据7,第9条,0002,U 7,数据7,第10条,0002,U入库脚本如下:
./load.sh -t ogg_test -p 20191231 -k uniqkey -dist -deletemark datastatus -tp txt -f b.txt -local -sp , -fl uniqkey,dataname,datapos,dataversion,datastatus入库结果为:
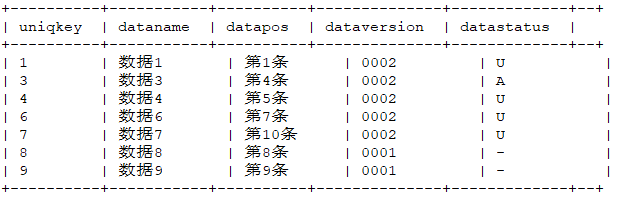
9. load统计工具
./load.sh -t common_example001 -p data_operate -tp txt -f /data/test/test_001.log -sp , -fl s1,i1,f1,l1,d1,ti1,tf1,tl1,td1,wc4_1,wc4_2 -isp /result/test
注:-isp后所跟参数为指定的数据入库统计结果存放路径(保存在hdfs内),用于记录错误数据及入库过程记录信息,该目录可由用户自定义,无需事先创建。
10. 导入脚本参数详解
| 参数 | 说明 |
|---|---|
| -t | (必选)LSQL中的表名。 |
| -f | (必选)HDFS的文件路径,与-local参数联合使用代表访问Linux本地文件路径。 |
| -tp | (必选)文件类型,目前支持txt和json。 |
| -fl | (txt格式必选)txt文件对应的表的列名字。 |
| -sp | (txt格式必选)txt文件对应分隔符,支持正则,不可见字符,可以通过urlencode编码。 |
| -p | (可选)LSQL中的分区名,如果不写,则导入到表的默认分区 |
| -local | (可选)Linux本地文件路径。 |
| -ov | (可选)导入前是否清空当前分区的数据。 |
| -k | (可选)按照该字段进行update覆盖,只支持不分词的索引列 |
| -ck | (可选)多个列做为主键,在导入数据时需预先通过-ck参数,将多个列的值生成联合值。参见“-kk -ck”用法。 |
| -kk -ck | (可选)当需要更新复合主键的时候通过-kk就可以根据-ck指定的多个列进行更新了,如果之前的数据没有根据-ck生成联合值,则不能进行多列更新。参见“-ck”用法。 |
| -kn | (可选)在使用-k更新数据时,可以选择-kn此条件,增加更新的并发度,设置更新的并发度可以提高更新的效率;一般设置2的倍数: -kn 4, -kn 8, -kn 10, -kn 16等。 |
| -cond | (可选)在追加数据前,先根据条件删除旧的数据。 |
| -delete | (可选)按照指定k列进行删除。 |
| -dist | (可选)表示按照key导入的时候进行数据排重,相同的key只保留在文件内偏移量最大的那个值。 |
| -deletemark | (可选)表示该条记录是否是被删除的记录,如果其值为 D or delete,会被删除,区分大小写,如果不是这两个值,会覆盖。 |
| -mvsplit SYS_TABLE_SPLITER_DEFAULT \%19 utf-8 | (可选)多值列数据分割符(\%19,支持其他的分割符)替换成LSQL支持的多值分隔符。对所有字段作用。 |
| -mvsplit 字段名字 \%19 utf-8 | (可选)多值列数据分割符(\%19,支持其他的分割符)替换成LSQL支持的多值分隔符。对指定字段作用。 |
| -isp | (可选)在导入数据时设置错误数据及入库过程记录信息路径。 |