8.1.4. SQL解析层介绍
1. LSQL与HIVE(Spark SQL)的关系
由于LSQL底层使用SPARK进行复杂业务SQL的计算,所以LSQL支持的SQL宏观可分为简单SQL和复杂SQL。
简单SQL为纯LSQL SQL(即LSQL层SQL)。复杂SQL为复合SQL,即一个SQL语句中同时使用了LSQL计算查询引擎和SPARK 计算查询引擎。
对于LSQL系统来说,我们将索引与SPARK集成在了一起,但是LSQL层的SQL解析与SPARK层的SQL解析是分别处理。
2. 什么是spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。SparkSQL的前身是Shark,Shark是伯克利实验室Spark生态环境的组件之一,它修改了内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
3. LSQL与spark的关系
LSQL的SQL统计也是基于spark,但lsql又增强了spark,主要体现在下面两个方面:
) 通过lucene给spark加了一层索引
索引技术大幅度的加快数据的检索速度。
索引技术可以显著减少查询中分组、统计和排序的时间。
索引技术大幅度的提高系统的性能和响应时间,从而节约资源。
) 让spark SQL可以实时导入数据,弥补了spark只能处理离线数据的不足。
因为spark支持复杂的SQL查询,所以lsql因为基于spark,故也支持复杂的SQL统计,但又有检索与facet的两个绝对优势。
4. 如何区分Spark的SQL解析层与LSQL的SQL解析层
(1) 从架构角度
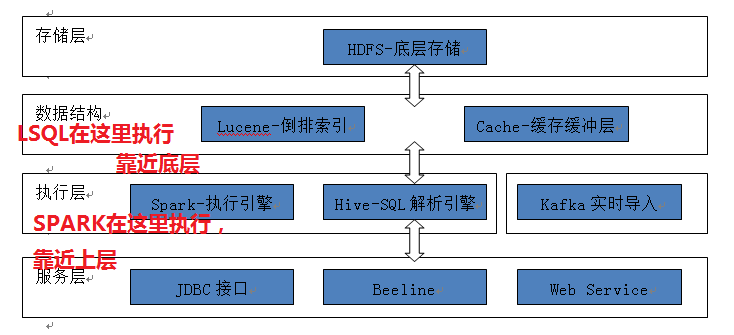
(2) 从SQL角度
在LSQL中,由系统自动识别SQL解析层,但是LSQL层的语法解析规则依然存在,请详细阅读下面的LSQL SQL编写思路。