6.13. 无需通过Producer向kafka推数据
本功能可以不通过kafka的Producer即可向kafka推数据从而使lsql能够消费到的场景。针对数据来源的正确性分为以下两种情况:
6.13.1. 数据格式正确
- 创建一个java工程,将lsql的包作为依赖添加进来,继承CLStreamConsumer方法并且实现NotProguardUser, NotEncrypt两个接口。

- 通过实现read方法,将生成的json数据return出去,lsql的paser类即可消费到。
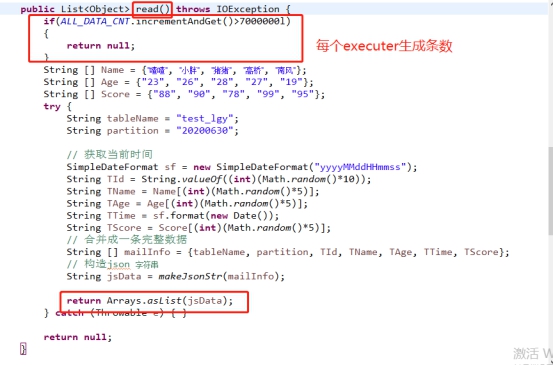
调用Main方法测试Return的json数据示例:
[{"tablename":"test_lgy","partition":"20200630","T_ID":"3","T_NAME":"猪
猪","T_AGE":"27","T_TIME":"20200630151424","T_SCORE":"78"}]
tablename:数据需要导入的表名
partition:需要导入的分区
T_ID、T_NAME、T_AGE、T_TIME、T_SCORE:表中的字段及数据
完整无误后就可以打包放在lsql的lib下(无需打入依赖包,打包大小为kb级)。
- 数据生产已经完成,只需在lsql-site.properties中添加consumer和paser即可
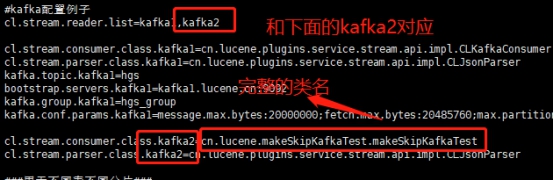
- 最后重启lsql,即可消费到数据(4个executer每个7000000数据,共入了28000000条数据)

6.13.2. 数据格式不正确
在现实生产环境中推进kafka的数据格式不正确的情况下,我们需要自己写paser类来使lsql消费kafka数据。
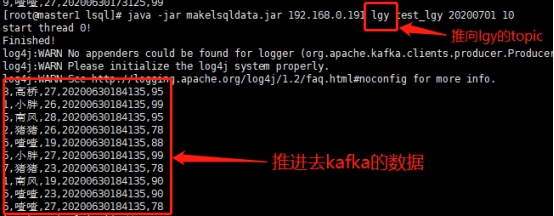
- 造一些不规则的数据推向kafka
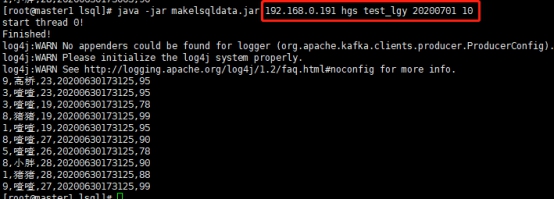
java -jar makelsqldata.jar 192.168.0.191 hgs test_lgy 20200701 10
192.168.0.191 hgs test_lgy 20200701 10分别代表kafka的ip,topic,表名,分区名,条数(表名和分区名在此处不起作用,因为我们的造数据本来就是不规则的)。
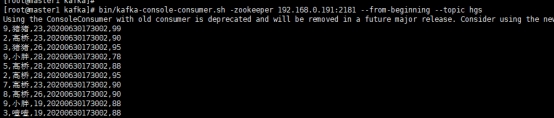
bin/kafka-console-consumer.sh -zookeeper 192.168.0.191:2181 --from-beginning --topic hgs
查看控制台消费到的数据,如下图所示。这样的数据无法进入lsql,我们需要自己写paser。
- 写paser类来使消费到的kafka数据转换成lsql能消费的格式
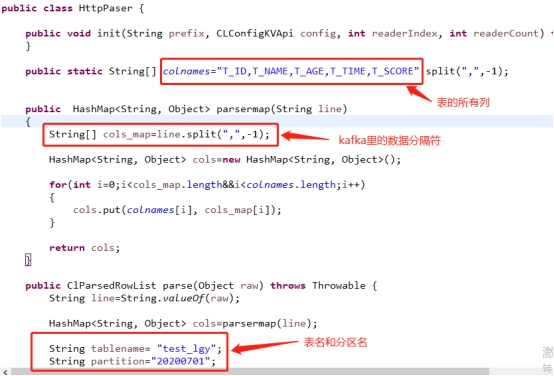
- 打包paser,放到lib下面并修改lsql-site.properties文件,指定paser类


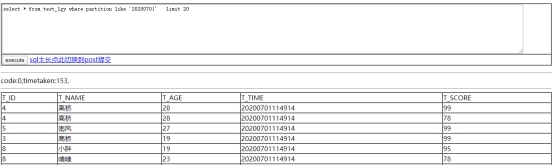
- 查询20200701分区,数据已成功入库。