6.16. 伴随分析、同行同住、时空碰撞
6.16.1. 数据准备
1. 建表示例
create table geo_bansui (
uuid y_string_id
,entry_id y_string_id
,position_str y_string_id
,position y_geopoint_idmp
,dest_tel y_string_id
,capture_time y_long_id
,type y_int_id
,entry_info y_string_id
,copy_geo y_keyword_ism
,copy_date y_keyword_ism
)
tableproperties(
ldrill=' olap_name@lname1 olap_key@copy_geo,copy_date olap_value@entry_id,capture_time,position_str,dest_tel,entry_info '
,ldrill=' olap_name@lname2 olap_key@dest_tel,copy_date olap_value@entry_id,capture_time,position_str,dest_tel,entry_info '
,copyfield='equals@position_str dest@copy_geo format@[g5]%s '
,copyfield='equals@capture_time dest@copy_date format@[min10]%s '
)
2. 关键字段解析

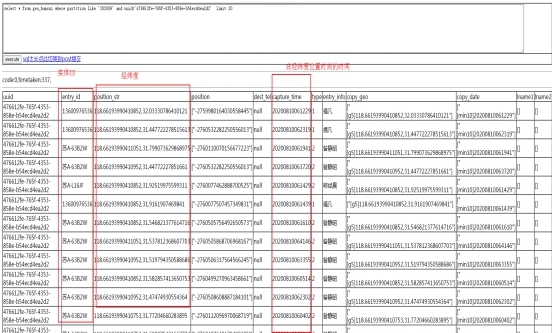
3. 数据预览
4. 伴随分析所依赖的多列联合索引说明
(1). 经纬度的解析

(2). 时间的解析
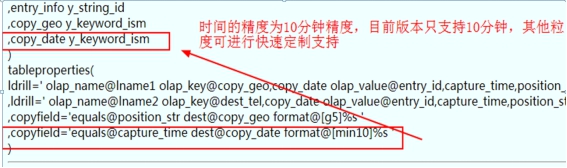
(3). 多列联合索引的创建

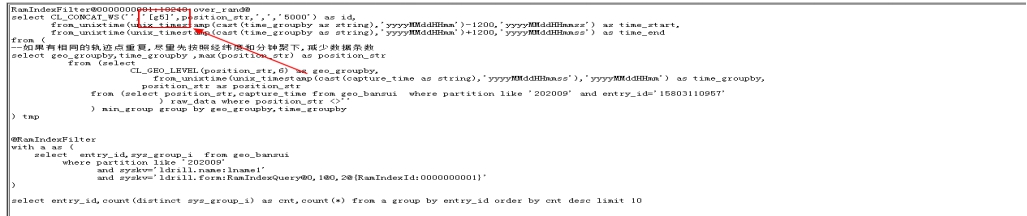
6.16.2伴随碰撞的SQL具体写法
RamIndexFilter@0000000001:10240:over_rand@
select CL_CONCAT_WS('','[g5]',position_str,',','5000') as id,
from_unixtime(unix_timestamp(cast(time_groupby as string),'yyyyMMddHHmm')-1200,'yyyyMMddHHmmss') as time_start,
from_unixtime(unix_timestamp(cast(time_groupby as string),'yyyyMMddHHmm')+1200,'yyyyMMddHHmmss') as time_end
from (
--如果有相同的轨迹点重复,尽量先按照经纬度和分钟聚下,减少数据条数
select geo_groupby,time_groupby ,max(position_str) as position_str
from (select
CL_GEO_LEVEL(position_str,6) as geo_groupby,
from_unixtime(unix_timestamp(cast(capture_time as string),'yyyyMMddHHmmss'),'yyyyMMddHHmm') as time_groupby,
position_str as position_str
from (select position_str,capture_time from geo_bansui where partition like '202009' and entry_id='15803110957'
) raw_data where position_str <>''
) min_group group by geo_groupby,time_groupby
) tmp
@RamIndexFilter
with a as (
select entry_id,sys_group_i from geo_bansui
where partition like '202009'
and syskv='ldrill.name:lname1'
and syskv='ldrill.form:RamIndexQuery@0,1@0,2@{RamIndexId:0000000001}'
)
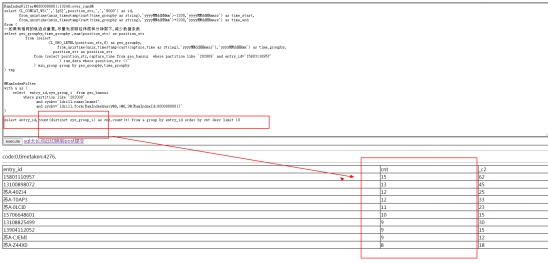
select entry_id,count(distinct sys_group_i) as cnt,count(*) from a group by entry_id order by cnt desc limit 10
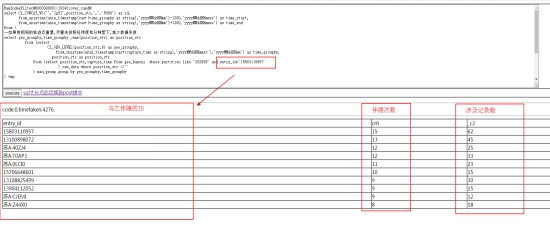
1. 返回的结果
2. SQL解释-第一步先查询一个ID的每个轨迹与时间
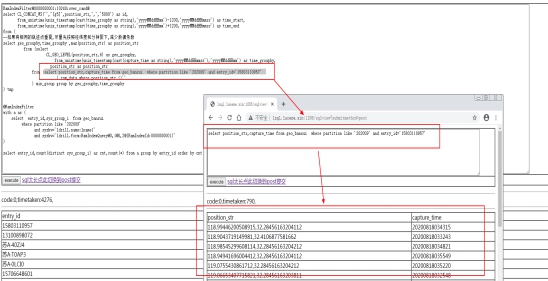
3. SQL解释-第二步将ID与时间按照已经粒度模糊-为第三部的数据合并做准备

4. SQL解释-第三步将一个ID的轨迹,按照相同的地点和时间合并
(地点为6精度的经纬度,时间为分钟)
合并的目的是考虑到基站数据与卡口数据不一样, 在一段时间内会有很多笔相同的重复记录。这些记录位于同一地点的连续的一段时间,将其合并成一条记录,有助于后续的匹配性能。
目前给的例子中,时间是按照分钟粒度合并的,其实并不是最优解。有的时候一个人可能会在某一个工位上连续座几个小时不更换地方(经纬度不变),这个连续的时间里可以完整的合并成一条记录。
但是那种合并需要额外写UDAF来实现连续片段的划分,并结合UDTF方式将不同片段进行列转行的操作,比较麻烦,这里仅仅为了演示用法,实际情况需要根据不同的业务标准划分连续片段。
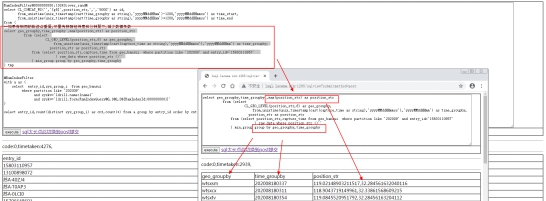
5. SQL解释-第四步最终得出一个ID的估计点和在每个轨迹点上的停留时间
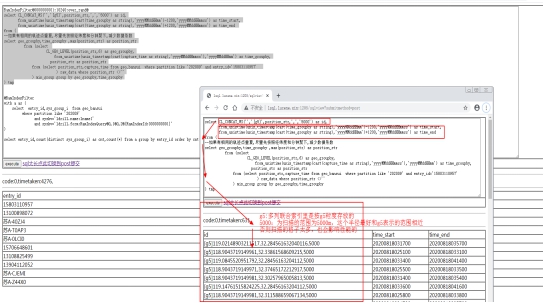
6. SQL解释-碰撞第一步,根据轨迹碰撞出每个轨迹点的数据
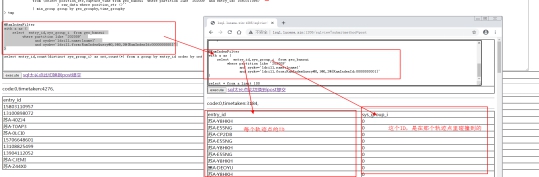
7. SQL解释-碰撞最后一步-通过distinct计算出每个ID的碰撞重叠次数
6.16.3注意事项
1. 建表语句里的位置精度与时间精度非常影响性能
如果精度太细会造成扫描个key的数量(格子)很多,影响性能。精度太粗,会影响准确性

2. 查询时候的位置精度,一定要与建表语句一直,这个精度决定了地理位置检索的方格粒度
3. 轨迹点合并也会对性能影响很大
轨迹点合并的精度,经纬度的范围,都会涉及扫描单元格的数量,如下图所示的几个位置
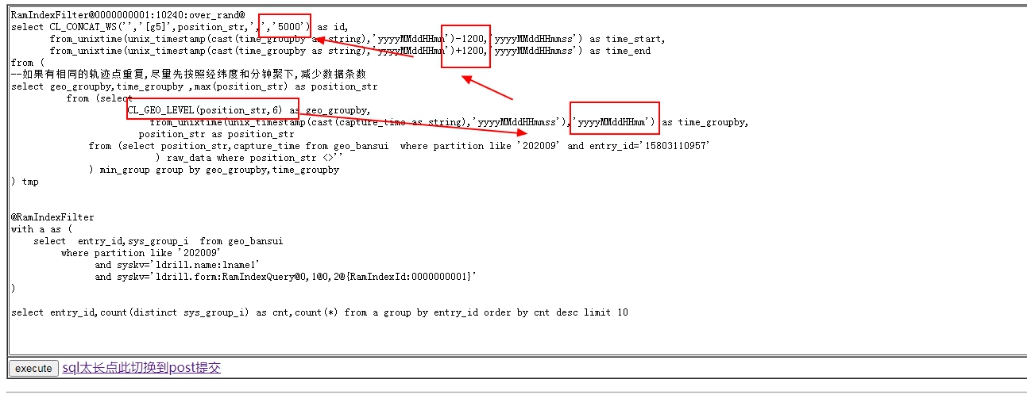
4. 日志中可以查看具体检索了哪些方格

5. 如何打印多列联合索引内部实际存放的数据格式
select copy_geo,copy_date,entry_id,sys_group_i from geo_bansui
where partition like '202009'
and syskv='ldrill.name:lname1'
and syskv='ldrill.from:SYS_URL_ENCODE@['wteue']@SYS_URL_ENCODE' and syskv='ldrill.to:SYS_URL_ENCODE@['wteue']@SYS_URL_ENCODE' limit 100
6. keyword分词的切词后的结果
select
CL_Analyzer('y_keyword_ism','index','[g5]118.66193990410852,32.03330786410121') as a1,
CL_Analyzer('y_keyword_ism','index','[min10]20200810061229') as a2