8.1.5. SQL编写的思路
LSQL所有sql查询都必须加上limit限制! 由于 LSQL 的LSQL执行引擎作用是直接对接数据索引的,充分利用索引进行过滤筛选,所以充分使用LSQL执行引擎可以极大的提升数据检索以及统计的效率。原则上在数据获取阶段,充分利用列存储机制,减少不需要列的返回,能够在LSQL 层过滤掉的数据就在LSQL层过滤,不要抛到SPARK 层过滤,LSQL层获取数据效率更高。
LSQL 层实现 COUNT、AVG、MAX、MIN、SUM 等功能的效率远高于SPARK 实现的效率。
1. LSQL的SQL解析层注意事项
LSQL层的作用是直接对接索引的,可以极大的提升数据检索以及统计的效率,功能简单,支持的函数并不多,目前函数仅仅内置COUNT、AVG、MAX、MIN、SUM五个分组聚合函数。
(1) LSQL SQL解析层能做什么
- 充分利用索引进行过滤筛选;
- 充分利用列存储机制,减少不需要列的返回;
- 利用索引实现高性能的like与not like匹配;
- 利用聚合函数COUNT、AVG、MAX、MIN、SUM进行必要的聚合,提升性能;
- 针对tlong,tint,tdouble,tfloat类型的列可以极大的提升范围过滤与topN排序的性能;
- 针对无排序的GROUP BY可以极大的提升高纬值列的分组性能;
- 针对维值不高的列可以结合GROUP BY+聚合函数减少返回给SPARK层的数量,从而提升能。
(2) LSQL SQL解析层限制
不可以进行SQL嵌套;
不可以进行多表关联;
不可以进行UNION操作;
除了COUNT、AVG、MAX、MIN、SUM外,其他函数一概不支持;
不支持自定义UDF、UDAF、UDTF的函数的写法;
不支持列与列之间的运算,大小比较,只支持上面的过滤写法;
不支持相同表名字的创建。若创建了相同表名的表,后创建的表结构会覆盖前面创建的表的结构(相同表明的创建用在修改表结构的场景下)。
(3) LSQL SQL解析层支持的过滤条件写法
- 等值匹配:
如 qq='165162897'
- 支持 in操作
如:indexnum in (1,2,3)
<,>,>=,<=,区间查询的写法:
clickcount >='10' and clickcount <='11'
对于带有范围的过滤筛选,使用下面的方式能提升查询效率
indexnum like ‘({0 TO 11})’ 不包含边界值
indexnum like ‘([10 TO 11] )’ 包含边界值
- 不等于的写法
label<>'l_14' and label<>'l_15'
- 过滤条件可以进行and与or的组合
indexnum='1' or indexnum='2' or (clickcount >='5' and clickcount <='11')
支持like与not like写法
支持 is null 与is not null写法
(3) LSQL SQL解析层支持的写法示例
- 查看数据例子
select S1,S2,I1,L1 from common_example001 where partition Like 'Teststream' Limit 5;
- 对某个列进行排序
select S1,S2,I1,L1 from common_example001 where partition Like 'teststream' And ( I1>'2' And I1<='5') order by S1 descl lmit 5;
- 对表进行简单的count统计
select count(*) from common_example001 where partition Like 'teststream' limit 20;
- 简单的统计函数
select sum(clickcount),avg(clickcount),max(clickcount),min(clickcount) from common_example001 where partition like 'teststream' limit 20;
- 分类汇总的写法group by
select label,count(*),sum(clickcount) from common_example001 where partition like 'teststream' Limit 20;
- 对分类汇总的结果进行排序
select Label,Userage,count(*),sum(Clickcount) from common_example001 where partition Like 'teststream' limit 20;
- 多列排序的写法
select Label,Indexnum from common_example001 where partition like 'teststream' order by Label desc,Indexnum limit 1000;
2. 简单SQL(纯LSQL SQL / 内SQL)
简单SQL为纯 LSQL SQL,SQL语句直接作用在LSQL计算引擎上用于统计、查询功能的实现。
直接作用在LSQL 表的统计语句如下:
SELECT COUNT(*) FROM QUICKSTART WHERE partition = '3000W' LIMIT 5 ;
直接作用在 LSQL 表的查询语句如下 :
SELECT ABC FROM QUICKSTART WHERE partition = '3000W' LIMIT 10;

用户提交的SQL是复杂SQL或是简单SQL,LSQL SQL解析器自定识别,自动调用相应的执行引擎。在执行的过程中如果SQL符合LSQL的SQL语法会优先使用LSQL执行引擎,否则会使用SPARK SQL的执行引擎。
3. 复杂 SQL(复合 SQL / 内外 SQL)
目前,LSQL计算引擎自身支持的SQL 函数为SUM、MAX、MIN、AVG、COUNT。除此之外的其他函数、自定义函数等暂不支持,同时多表关联也不支持。
显然多表关联、复杂函数在实际的项目中经常用到。为支持多表关联、以及复杂的函数、自定义函数等LSQL引入SPARK,借助SPARK的计算能力实现多表关联、复杂函数、自定义函数等。
复杂SQL为复合SQL,用户提交的SQL语句部分作用在LSQL计算引擎上,部分作用在SPARK计算引擎上,以此实现复杂计算(多表关联、复杂函数、自定义函数)用于统计、查询功能的实现。哪部分作用在LSQL,哪部分作用在SPARK,LSQL SQL 解析器自动判断。
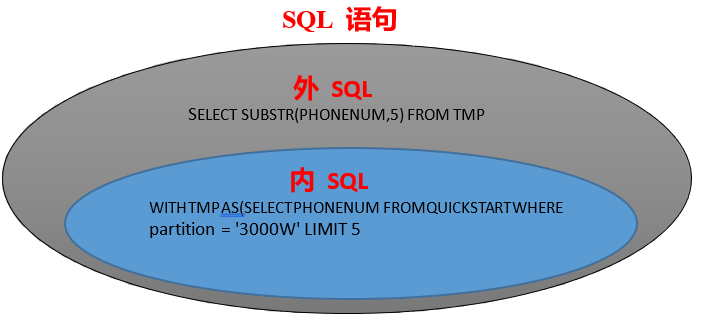
例如:LSQL 有一张表,表名为“QUICKSTART”,对此表的“PHONENUM”字段进行截取 SQL 语句如下。
WITH TMP AS
(SELECT PHONENUM FROM QUICKSTART WHERE partition='test' LIMIT 5)
SELECT SUBSTR(PHONENUM,5) FROM TMP ;
内 SQL、简单 SQL 为“WITH TMP AS(SELECT PHONENUM FROM QUICKSTART WHERE partition = '3000W' LIMIT 5)”直接作用在LSQL 中。
外 SQL 为“SELECT SUBSTR(PHONENUM,5) FROM TMP”作用在 SPARK。
执行过程为内层SQL 直接作用在LSQL引擎进行数据获取或过滤,拿到数据后抛给外层SPARK 层,数据截取等操作由SPARK 来执行。
LSQL 自身不支持“字符串截取”功能,借助SPARK 可以实现此功能。