4.5.6 导出到其他表
1. 先创建一个普通hive表
CREATE external table facet_h(
id bigint, name string, sex string,age int,education string,city string
)
PARTITIONED BY (date_test string)
STORED AS PARQUET
LOCATION '/data/example/facet_h'
TBLPROPERTIES (
'parquet.compression'='gzip');
facet_h:hive表名
date_test:自定义分区名
PARQUET:存储类型为parquet
/data/example/facet_h:在HDFS上的存储路径
gzip:针对存储启用gzip压缩。支持压缩类型:"uncompressed", "snappy", "gzip", "lzo"。Snappy压缩具有更好的性能,Gzip压缩具有更好的压缩比。

图 4.5.6.1创建hive表
2. 将数据导出到对应的hive表(注意lsql的嵌套)
insert overwrite table facet_h partition(date_test='20200619')
select * from (
select id,name,sex,age,education,city from facet where partition = 'default'
) tmp;
20200619:hive表数据指定入到20200619这个分区
default:原lsql表数据存在默认分区中
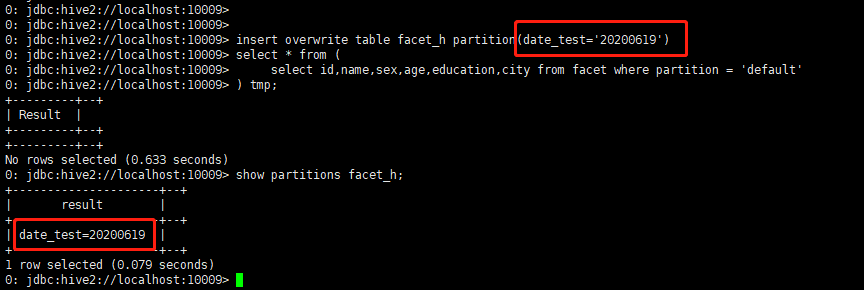
图 4.5.6.2 导入数据
3. 查看表数据
(1) 原lsql表
select * from facet limit 5;
select count(*) from facet;
desc facet;
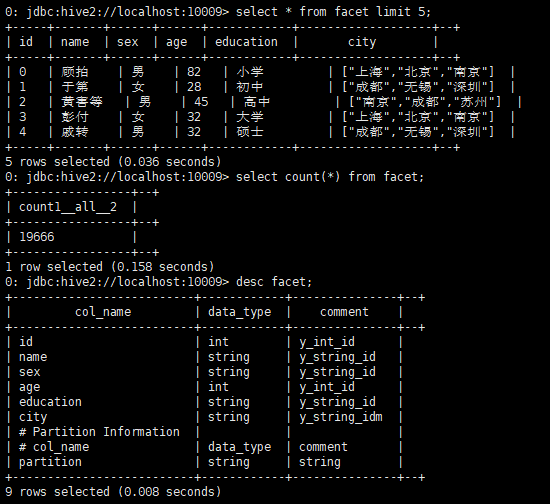
图 4.5.6.3查询表
(2)Hive表
select * from facet_h where date_test='20200619' limit 5;
select count(*) from facet_h where date_test='20200619';
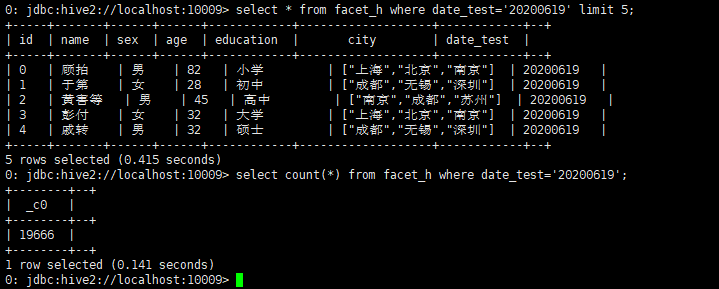
图 4.5.6.4
(3)查看hdfs目录
启用gzip压缩(facet_h表)
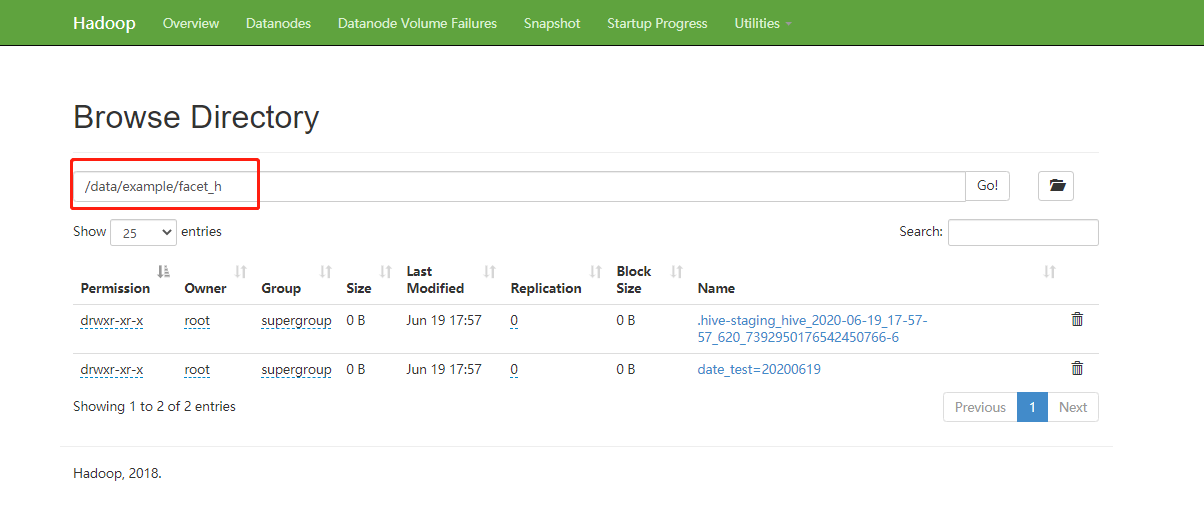
图 4.5.6.5
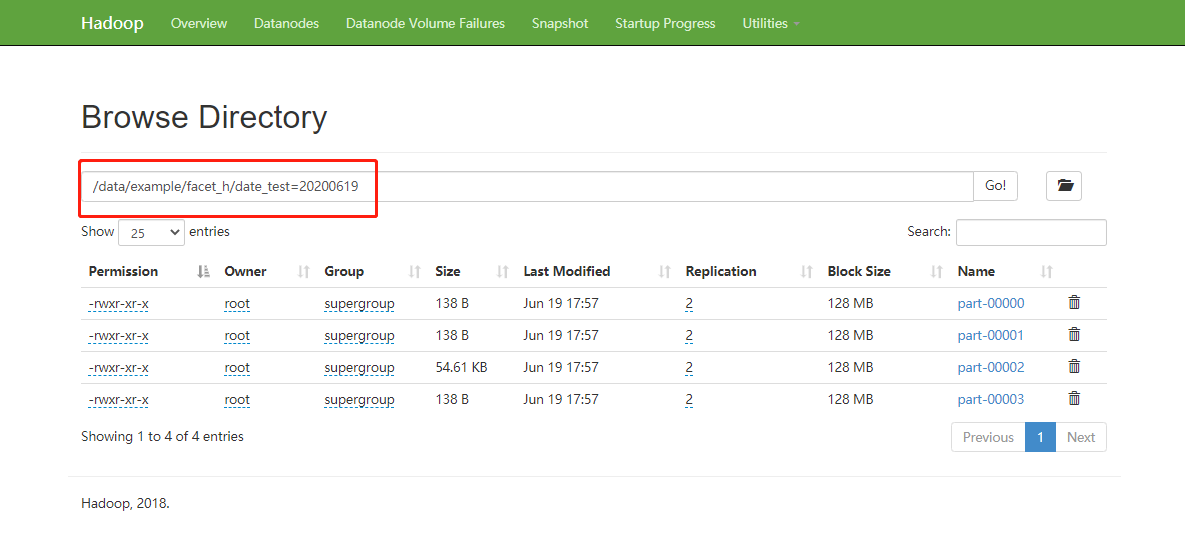
图 4.5.6.6启用gzip压缩
未启用gzip压缩(facet_h2表)
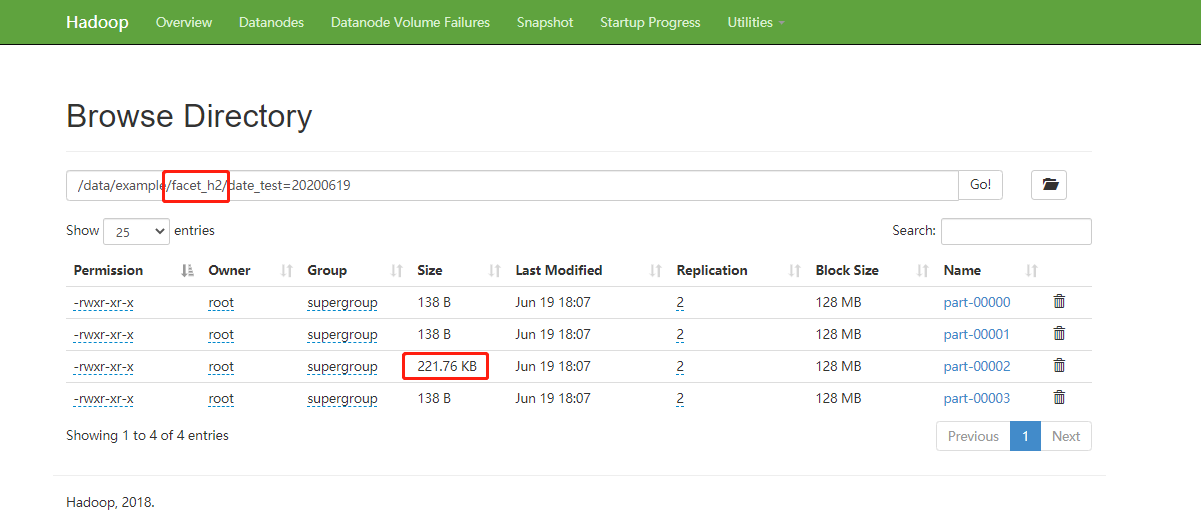
图 4.5.6.7未启用gzip压缩
通过对比可发现,使用gzip压缩降低了约75%的存储。